
Here I introduce an introductory overview of quantitative information flow (QIF), a mathematical framework used to precisely discuss leakage. We start with a system that takes some sensitive information as input, processes it, and produces some publicly observable output. We want to determine how the system affected the sensitive information. This overview will focus on the often relevant and intuitive measure of Bayes vulnerability, which addresses when the adversary must guess the value of the secret correctly in one try.
I geared this description to people who are mostly unfamiliar with Bayesian statistics, who may be taking a class on formal foundations of cybersecurity, or who are reading a paper that mentions these topics and just want everything broken down a little. Future posts will discuss the flexibility of QIF to model different operational scenarios. For now, I only want to provide some intuition. The following notation and some of the examples are taken from The Science of Quantitative Information Flow (2020).
Bayes Vulnerability
We are concerned with protecting a secret 


Let’s assume the adversary only knows 

For example, the secret could be a four-digit pin. There are 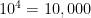
At this point, we make the adversary guess our pin. She knows the possible values of our pin and she also knows that they are all equally likely. She will then make the best guess according to 
Now in reality we know that some pins are vastly more popular than other ones. Let’s set the probability of pin 1-1-1-1 to 1/2 and keep the other pins all equally likely so that
Now let’s make the adversary guess our pin. Her optimal strategy is to choose the secret that has the highest probability of occurring. With this strategy, she’ll guess our pin is 1-1-1-1 and she’ll be correct 1/2 of the time so 
Channels
Now let’s consider a system that processes a secret 
We call this system a channel. We can reason about all possible input and output values of a channel by representing it in a channel matrix. The entry 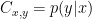
For now, let’s consider deterministic channels where every secret leads to only one possible output value. This means that every row of C will have one 1 and the rest of the entries are 0s.
For example, let our secret be the roll of one white dice and one red dice and let the observable output be the sum of these two dice. The channel matrix looks as follows (empty boxes are 0s, but I didn’t display these to help readability):

Let’s assume that these are fair dice and so every secret is equally likely with probability 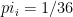



From here, we can figure out the probability of each output y by summing the columns of J. This is called the marginal distribution 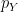
Hyper-Distribution
With J, we can figure out 
To do this, we normalize the columns of J by summing the columns and then multiplying each entry by the reciprocal of this sum. If we replace the actual values of y by their probabilities 
![[\pi \triangleright C]](https://s0.wp.com/latex.php?latex=%5B%5Cpi+%5Ctriangleright+C%5D&bg=ffffff&fg=000&s=0&c=20201002)

Let’s walk through this hyper-distribution.
Firstly, we notice that there are 11 different states of knowledge that an adversary can end up in. With probability 1/36, she’ll end up in the first world. This corresponds to when she sees the output 2. With probability 2/36, she’ll end up in the second world, which corresponds to when she sees the output 3. From this hyper-distribution, we can see that she’s most likely going to see output 7 with probability 6/36.
Next, let’s look at the 11 different posterior distributions, represented by the 11 columns in the hyper-distribution. The adversary most likely going to see output 7 with probability 6/36. The posterior distribution in this world is (0, 0, 0, 0, 0, 1/6, 0, 0, 0, 0, 1/6, 0, 0, 0, 0, 1/6, 0, 0, 0, 0, 1/6, 0, 0, 0, 0, 1/6, 0, 0, 0, 0, 1/6, 0, 0, 0, 0, 0). She can narrow down the secret to six values, each with equal probability.
In contrast, the world represented by the first column only happens 1/36 of the time. However, when it does happen, the adversary knows the secret with absolute certainty. Only the dice roll (1, 1) could have produced it.
Posterior Bayes Vulnerability
Now we have modeled the effect of the channel and we want to quantify the ‘threat’ to the secret. To do so, we can calculate the Bayes vulnerability for every posterior distribution, weighed by the likelihood of that distribution. We call this posterior Bayes vulnerability and denote it by ![V_1 [\pi \triangleright C]](https://s0.wp.com/latex.php?latex=V_1+%5B%5Cpi+%5Ctriangleright+C%5D&bg=ffffff&fg=000&s=0&c=20201002)
![V_1 [\pi \triangleright C] = \sum_{y} p(y) V_1(p(X|y)](https://s0.wp.com/latex.php?latex=V_1+%5B%5Cpi+%5Ctriangleright+C%5D+%3D+%5Csum_%7By%7D+p%28y%29+V_1%28p%28X%7Cy%29&bg=ffffff&fg=000&s=0&c=20201002)
In our example,
![V_1 [\pi \triangleright C] = \frac{1}{36} (1) + \frac{2}{36} (\frac{1}{2}) + \frac{3}{36} (\frac{1}{3}) + \frac{4}{36} (\frac{1}{4}) + \frac{5}{36} (\frac{1}{5}) + \frac{6}{36} (\frac{1}{6}) + \frac{5}{36} (\frac{1}{5}) + \frac{4}{36} (\frac{1}{4}) + \frac{3}{36} (\frac{1}{3}) + \frac{2}{36} (\frac{1}{2}) + \frac{1}{36} (1) = \frac{11}{36}](https://s0.wp.com/latex.php?latex=V_1+%5B%5Cpi+%5Ctriangleright+C%5D++%3D+%5Cfrac%7B1%7D%7B36%7D+%281%29+%2B+++%5Cfrac%7B2%7D%7B36%7D++%28%5Cfrac%7B1%7D%7B2%7D%29+%2B+++%5Cfrac%7B3%7D%7B36%7D+++%28%5Cfrac%7B1%7D%7B3%7D%29++%2B+++%5Cfrac%7B4%7D%7B36%7D+++%28%5Cfrac%7B1%7D%7B4%7D%29++%2B+++%5Cfrac%7B5%7D%7B36%7D+++%28%5Cfrac%7B1%7D%7B5%7D%29++%2B+++%5Cfrac%7B6%7D%7B36%7D++%28%5Cfrac%7B1%7D%7B6%7D%29++%2B+++%5Cfrac%7B5%7D%7B36%7D+++%28%5Cfrac%7B1%7D%7B5%7D%29++%2B+++%5Cfrac%7B4%7D%7B36%7D++%28%5Cfrac%7B1%7D%7B4%7D%29+++%2B+++%5Cfrac%7B3%7D%7B36%7D+++%28%5Cfrac%7B1%7D%7B3%7D%29++%2B+++%5Cfrac%7B2%7D%7B36%7D+++%28%5Cfrac%7B1%7D%7B2%7D%29++%2B++++%5Cfrac%7B1%7D%7B36%7D++%281%29+%3D+%5Cfrac%7B11%7D%7B36%7D&bg=ffffff&fg=000&s=0&c=20201002)
This illustrates an interesting property of posterior Bayes vulnerability under a uniform prior: it is always the number of possible output values over the number of possible secrets.
Another interesting fact is that posterior Bayes vulnerability can be calculated directly from J by simply summing the column maximums:
![V_1 [\pi \triangleright C] = \sum_y \max_x J_{x, y}](https://s0.wp.com/latex.php?latex=V_1+%5B%5Cpi+%5Ctriangleright+C%5D+%3D+%5Csum_y+%5Cmax_x+J_%7Bx%2C+y%7D&bg=ffffff&fg=000&s=0&c=20201002)
Bayes Leakage
We can identify how much a channel ‘leaked’ by comparing prior and posterior Bayes vulnerability. If we want to examine the relative difference, we calculate the multiplicative Bayes leakage
![\mathcal{L}_1^{\times} = \frac{V_1 [\pi \triangleright C]}{V_1(\pi)}](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BL%7D_1%5E%7B%5Ctimes%7D+%3D+%5Cfrac%7BV_1+%5B%5Cpi+%5Ctriangleright+C%5D%7D%7BV_1%28%5Cpi%29%7D&bg=ffffff&fg=000&s=0&c=20201002)
and if we want to compute the absolute difference, we calculate the additive Bayes leakage
![\mathcal{L}_1^{+} = V_1 [\pi \triangleright C] - V_1(\pi)](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BL%7D_1%5E%7B%2B%7D+%3D+V_1+%5B%5Cpi+%5Ctriangleright+C%5D+-+V_1%28%5Cpi%29&bg=ffffff&fg=000&s=0&c=20201002)
In our example,

and
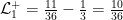
Again, this illustrates another interesting property under a uniform prior with a deterministic channel: the multiplicative Bayes leakage is always the number of outputs and the additive Bayes leakage is the number of outputs minus 1 over the number of secrets.
What does this mean? Our channel leaked information. Knowing the channel, the adversary is 11 times more likely to correctly guess the secret in one try.
What’s next?
Bayes vulnerability corresponds to only one operational scenario. QIF lets us define gain functions that let us model a variety of operational scenarios, such as when the adversary actually has three tries to guess the secret, or when she has to guess a particular attribute of the secret. With these functions, we can evaluate the effect of a channel with g-vulnerability and g-leakage.
QIF also has some interesting robustness concepts such as multiplicative Bayes capacity, which establishes the upper bound on multiplicative Bayes leakage regardless of prior or gain function. Another important concept is refinement in which we can say whether one channel never leaks more than another regardless of prior or gain function.

